
Last week I said I would change the design of my strategy performance summaries to help compare better around the blogosphere, so here is the first example with it.
This strategy is also to show that sometimes we are so focused on the US securities market that we miss some attractive investment opportunity. As a matter of fact, I am particularly guilty on this one. I usually study the S&P 500 and its futures in my research. However for this one, I turn home to look at an ETF for Canadian Government Bonds (Yahoo ticker: XGB.TO) introduced to me in one of my classes. I tested a simple DV2 strategies using entry/exit at .5 and traded the strategy long and short. The results are below.



The results were impressive for such a simple strategies, the risk vs. return profile is also very good, I usually wouldn’t share a strategies with such good results but since it is so simple I figured why not. However, be careful with this, transaction costs would definitely impact performance. As a closing thought, I encourage you to look for trading ideas in places where you normally wouldn’t as you might be surprised by the results.
Lastly, in the post where I discuss the new strategy report, Freeman commented and made a valid point:
QF-For the Sortino Ratio why not set the MAR equal to the benchmark’s historical returns for the period under consideration? It appears unrealistic to set an acceptable %-return at 0 given the opportunity costs associated with trading any strategy. The above suggestion is just one way (albeit a simple one) to consider given the hypothetical alternatives one could have had at the time a strategy was executed.
So basically, here is the trade off, we either base the Sortino ratio on the excess return, or simply take the unprocessed return over the downside deviation. Both have their advantages, if we use the excess return, we take into account the opportunity cost of trading the strategy vs. buy and hold the benchmark. If we decide to compute the ratio using the normal return series, we gain the opportunity to put it in perspective with the Sharpe ratio as currently computed (Rf = 0%). We would basically get the Sharpe ratio computed only with the downside deviation (ie. no penalty for upside volatility). Alternatively, I could compute both measures with the excess return series. I would like reader feedback on this, so if you would just let me know in the comment section what you would prefer for the ratios and also what you think of the new performance summary as a whole, it would help me make it better for you!
QF
 . Intuitively, we can question this assumption; I, for one, would argue that not only the magnitude but also the direction of the returns affects volatility. In plain English: negative shocks (events/news, etc.) tend to impact volatility more than positive shocks. Think about the asymmetric nature of the VIX (see
. Intuitively, we can question this assumption; I, for one, would argue that not only the magnitude but also the direction of the returns affects volatility. In plain English: negative shocks (events/news, etc.) tend to impact volatility more than positive shocks. Think about the asymmetric nature of the VIX (see 

 and
and 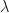 are coefficients, and
are coefficients, and  comes from a generalized error distribution.
comes from a generalized error distribution.
 statistic of 179.4636, significant at the .05 confidence level. We are now statistically confident in the presence of ARCH effect in our data.
statistic of 179.4636, significant at the .05 confidence level. We are now statistically confident in the presence of ARCH effect in our data.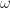 = 4.604e-06,
= 4.604e-06,  = 3.090e-01 and finally
= 3.090e-01 and finally 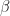 = 6.485e-01. Now that we have the model, we can forecast our standard deviation (volatility). After this step is completed, we want to find the 1 percent quantile of our volatility for our VaR. We obtain 0.003995719, now to find our VaR we have a choice on the distribution assumption. We can assume it is normally distributed and multiply this by 2.327, because 1 percent of a normal random variable lays 2.327 standard deviations below the mean. Now I don’t like that since I usually prefer to steer clear of the normality assumption when dealing with financial data. I would rather use the empirical distribution of the error observed in my model. Simply standardize the model residual and observe its empirical distribution to find the 1 percent quantile; we obtain a result of 2.619797.
= 6.485e-01. Now that we have the model, we can forecast our standard deviation (volatility). After this step is completed, we want to find the 1 percent quantile of our volatility for our VaR. We obtain 0.003995719, now to find our VaR we have a choice on the distribution assumption. We can assume it is normally distributed and multiply this by 2.327, because 1 percent of a normal random variable lays 2.327 standard deviations below the mean. Now I don’t like that since I usually prefer to steer clear of the normality assumption when dealing with financial data. I would rather use the empirical distribution of the error observed in my model. Simply standardize the model residual and observe its empirical distribution to find the 1 percent quantile; we obtain a result of 2.619797.

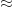 97%). It looks as if the VaR measure was mostly conservative for the period. There you have it; I hope that this step by step application post was useful and clear and that it sheds a bit of light on an at times obscure topic. Stay tuned for the last post in this series on EGARCH.
97%). It looks as if the VaR measure was mostly conservative for the period. There you have it; I hope that this step by step application post was useful and clear and that it sheds a bit of light on an at times obscure topic. Stay tuned for the last post in this series on EGARCH. ). As mentioned in one of my all time favorite blog post:
). As mentioned in one of my all time favorite blog post: 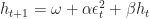
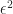 the squared residual, and t the period. The constants
the squared residual, and t the period. The constants 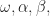 must be estimated and updated by the model every period using maximum likelihood. (The explanation for this is beyond the scope of this blog, I recommend using statistical software like R for implementation.) Additionally, one could change the order to change the number of ARCH and GARCH terms included in your model. Sometimes more lags are needed to accurately forecast volatility.
must be estimated and updated by the model every period using maximum likelihood. (The explanation for this is beyond the scope of this blog, I recommend using statistical software like R for implementation.) Additionally, one could change the order to change the number of ARCH and GARCH terms included in your model. Sometimes more lags are needed to accurately forecast volatility.