
As request by several readers in light of the previous series of post on using GARCH(1,1) to forecast volatility, here is a very basic introduction post on two models widely used in finance: the GARCH and EGARCH.
One of the great tools of statistics used in finance is the least square model (not exclusively the linear least squares). For the neophyte, the least square model is used to determine the variation of a dependant variable in response to a change in another variable(s) called independent or predictor(s). When we fit a model, the difference between the predicted value and the actual value is called the error term, or residual, it is denoted by the Greek letter epsilon (
When we fit a model, we are, or I am anyway (!), interested in analyzing the size of errors. One of the basic assumptions of the least square model is that the squared error (squared to eliminate the effect of negative numbers) stays constant across every data point in the model. The term used for this equal variance assumption is homoskedasticity. However, with financial time series variance (read volatility or risk) cannot always be assumed constant, browsing through financial data, we can see that some periods are more volatile than others. Keeping this in mind, when fitting a model, this translates to a greater magnitude in the residuals. In addition, these spikes in variance are not randomly placed in time; there is an auto-correlation effect present. In simple terms, we call it volatility clustering, meaning that periods of high variance tend to group up together; think VIX spikes for example. Non-constant variance is referred as heteroskedasticity. This is where the GARCH model comes in, and helps us find a volatility measures that we can use to forecast the residuals in our models and relax the often flawed equal residuals assumption.
Before talking about the GARCH model, I have to quickly introduce its very close cousin, the ARCH (autoregressive conditional heteroskedasticity) model. Consider what must be the easiest way to forecast volatility; the rolling x day standard deviation. Say we look at it on a yearly (252 days) basis. Equipped with the value of this historical standard deviation we want to forecast the value for the next day. Central tendency statistics tells us that the mean is the best guess. I can already hear some of you cringe at the idea.
Using the mean, every 252 observation is equally weighted. However, wouldn’t it make more sense for the more recent observations to weight more? We could perhaps use an exponentially weighted average to solve this problem, but still isn’t the best solution. Another observation could be made about this method; it forgets any data points older than 252 days (their weight is 0). This weighting scheme is not the most desirable for quantitatively oriented investors as they are rather arbitrary. In comes the ARCH model where the weights applied on the residuals are automatically estimated to the best parameters (David Varadi would call it level 1 adaptation). The generalized ARCH model (GARCH) is based on the same principle but with time, the weights get progressively smaller, never reaching 0.
In the previous series of post, I used the GARCH model of order (1,1). Defined like this, the model predicts the period’s variance by looking at the weighted average of the long term historical variance, the predicted variance for the period (second 1, also called the number of GARCH terms) and the previous day squared residual (first 1, also called number of ARCH terms). Or more formally:
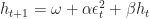
Where h denotes variance, 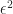
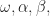
Caution is to be exercised by the user; this is not an end all be all method and it is entirely possible for resulting prediction to be completely different than the true variance. Always check your work and perform diagnostic tests like the Ljung box test to confirm that there is no auto-correlation left in the squared residuals.
Few, it was a long one, I hope that the first part of the post, made the GARCH model more approachable and that this introduction was useful. I encourage you to comment if areas of the post could be made clearer. Finally, stay tuned for part 2 where I am going to give another example of GARCH(1,1) for a value-at-risk estimation (a fairly popular application in academic literature) and part 3 on the EGARCH!
QF

Excellent explanation; You found the right balance between academic and practitioners alike. Spot-on!
Thank you,
-Mark-
Thank you Mark, I really appreciate the feedback !
Cheers,
QF
Should there be the h_t in the second term?
Hi mg,
In short no, could you give more details as to why? Just to clarify this is a model of order (1,1); only one ARCH and GARCH term. Let me know it is still confusing.
Cheers,
QF
I see a h_t in the second term, which doesn’t look right.
!! you are correct. I apologize for not catching it before and thank you for pointing it out. It was my first time using latex!
Cheers,
QF
No worries, just a silly typo. Thanks for sharing and writing on these topics.
Very informative post. Recently stumbled upon your blog and am impressed. Thank you for your time/effort and very much look forward to future contributions.
If a successful discretionary trader was just starting to consider a more robust & quantitative prototyping/modeling platform with very little programming experience… any strong preferences among matlab, octave or R? R is financially most attractive, but time/learning curve represent their own hidden cost. Matlab documentation appears excellent but unsure if the license cost is worth it over long haul. I’m an independent non-quant background using TT X-trader execution, CQG charting, and Tradestation (EasyLanguage) back/forward simulation. Interested in sampling other ways to trade futures/ccy markets that complement current strats. Any input much appreciated.
Hi BlackSwan,
Thank you for nice words and the question. I didn’t try much in terms of platforms so I can only comment on what I know. I do have a strong preference towards R compared to matlab (the savings do it for me). For the learning curve, I think R’s is fairly steep, I found learning the basics easy. I am in no way an expert and get stuck from time to time but every time someone in the great R community already answered the problem online. For research R is a must if you ask me, the quality of libraries available for quantitative finance is just amazing. However I never tried to implement a strategy using R, I hear the IBroker compatibility is in development; I am impatiently waiting! Hope this helps.
Cheers
QF
Thx QF,
I was looking for a comprehensive introduction to GARCH and your post fits my need perfectly. I am impatient to read the next parts.
Eric
Hi EajkEajk – thank you for the kind comment.
Cheers,
QF
Hi QF, I’m following you to test GARCH model of volatility. To see the fitness of model, I need to compare the model prediction and realized volatility, which depends on a given time window of historical returns, for example, 10 days of historical returns. It seems that a short time window gives a better fitness than a long time window, do you think so?
Hi Justin,
Just to make sure I understand your question correctly, you are talking about mean out-of-sample right? If so, then yes the model performs better in the beginning of the period as we would expect it since the model was recently trained.
Cheers,
QF
THX QF.
Excuse me for my obscure words. I am not a native English speaker so that I don’t express myself well :D. What I was trying to say is to do in-the-sample comparison. I compared the garch volatilities with the true volatilities. However, to calculate the true vol, I need to decide the number of days to do calculation. If I use 10 days of returns to calculate the true vol, it seems that it matches the garch vol well. If I use 60 days, the match is not so good. So is there a thumb rule for the choice of number of days? It seems that the shorter, the better
Hi Justin,
Good question, I usually use 20-21 days, but note that this is a completely arbitrary choice.
Cheers,
QF
Check this out from U Chicago. http://faculty.chicagobooth.edu/john.cochrane/research/Papers/time_series_book.pdf
I got it from Reddit, I would say it’s the clearest introduction to ARMA around.
Very nice, thanks a lot!
QF
Any idea how you would use the GARCH model in testing the Day of the Week effect anomaly?
I recently got introduced to GARCH and its predictive aspect by one my students and my interest in it has piqued partly as a academic reasons (I teach C++) and partly for its applicability in a stock market. Although, I am a novice in financial stats and greek symbols but I have read about 20-30 blogs/PDFs on GARCH in past 1 week and also thumbed thru quantlib implementation. I have come to realize that the three greeks (alpha, omega and beta) are constants that are parameters being fed into the model. So, naturally, the most important question is what are the most optimal values for these three. And 2nd most important question is how do you use it to predict high/low for the very next-day.
I did read your blog again after initial comment. What exactly does “maximum likelihood” mean?